Getting Started with Machine Learning: Starting at the End by understanding Rasa NLU


Getting started with Machine Learning is a daunting task. Where do I start in this complex maze? Should I start in the center or at the edges? Math or Algorithms?
What made sense was to start at the end. But what end? There are many projects that have been built with ML. So, which one do I choose? The choice was made easier for me when Bhavani Ravi was working to understand a project that has already built using Machine Learning for Natural Language Processing (NLP) — Rasa NLU. My interest in NLP was at an all time high because of my recent project in chatbots. This was serendipity, two mangoes with one stone.
What does Rasa NLU do? Rasa NLU is a tool for understanding what is being said in short pieces of text. For example, by taking a short text message like:
“I’m looking for a Chinese restaurant in my area”
It returns structured data like:
intent: search_restaurant
entities:
- cuisine : Chinese
- location : my areaBeginning at the Start
First, we looked at the command that should be executed to start training of our model:
python -m rasa_nlu.train \
--config sample_configs/config_spacy.yml \
--data data/examples/rasa/demo-rasa.json \
--path projects
This led us to the train.py in the rasa_nlu folder. Thats where all the magic happens (or atleast the training in this case). Digging deeper, we found the do_train() function, which is called on executing the above command. It takes the config, data and path specified during execution.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| def do_train(cfg, # type: RasaNLUModelConfig | |
| data, # type: Text | |
| path=None, # type: Optional[Text] | |
| project=None, # type: Optional[Text] | |
| fixed_model_name=None, # type: Optional[Text] | |
| storage=None, # type: Optional[Text] | |
| component_builder=None, # type: Optional[ComponentBuilder] | |
| url=None, # type: Optional[Text] | |
| **kwargs # type: Any | |
| ): | |
| """Loads the trainer and the data and runs the training of the model.""" | |
| trainer = Trainer(cfg, component_builder) | |
| persistor = create_persistor(storage) | |
| if url is not None: | |
| training_data = load_data_from_url(url, cfg.language) | |
| else: | |
| training_data = load_data(data, cfg.language) | |
| interpreter = trainer.train(training_data, **kwargs) | |
| if path: | |
| persisted_path = trainer.persist(path, | |
| persistor, | |
| project, | |
| fixed_model_name) | |
| else: | |
| persisted_path = None | |
| return trainer, interpreter, persisted_path |
Trainer
Now, in the do_train() function, we see that the Trainer model is initially called.
trainer = Trainer(cfg, component_builder)
Two arguments are passed to the Trainer model in model.py:
- config (sample_configs/config_spacy.yml) to use for the training, and
- component_builder, which is the pipeline specification. In our case, we had not specified the component_builder.
The Trainer basically loads the config and uses the component_builder to build a trainer model. As we had not specified the component_builder, the default spaCy component pipeline is loaded for us because of the specified spaCy config.
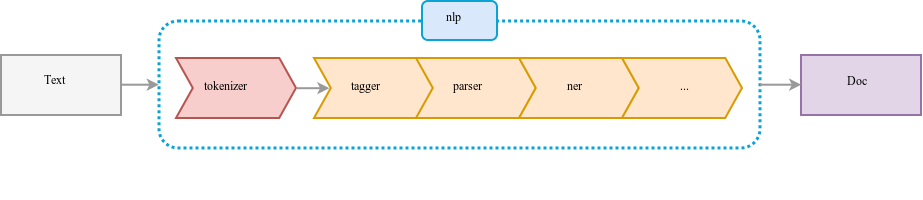
Persistor
The next function is the persistor, which functions to store the data. You can specify AWS, GC, Azure or None. This is optional and we did not specify the same.
persistor = create_persistor(storage)
Training Data
Next, the training data can be taken from either the url or from local. We had specified the data in local with our command (data/examples/rasa/demo-rasa.json).
if url is not None:
training_data = load_data_from_url(url, cfg.language)
else:
training_data = load_data(data, cfg.language)
Interpreter
This data is sent to the trainer, we had created above for training and generating an interpreter.
interpreter = trainer.train(training_data, **kwargs)
The train() function in the Trainer model gets the training_data and iterates through it to generate a spaCy model. This is returned as the interpertor, which can interpret the input data and give structured data output.
Persisted Path
If path is provided, as in our case (projects) data is persisted to the path.
The Result
And finally, the do_train() function returns the trainer, the interpreter and the persisted_path. Now, we can make use of the generated interpreter for getting intents and the entities. This can further be used for Natural Language Understanding, which is what is used in the Rasa core.

Equipped with this knowledge of how a trainer works in a final NLP product, I began my journey deeper into Machine Learning. I do have more questions than when I started, but at least now I know where to look and what direction to take. So, sometimes, it is better to start at the end and then go back to the beginning. This way you will get a load of questions, which will help you direct your focus towards a path that will take you in deeper.
Hope this article helped you also get started or enhanced your experience with Machine Learning. Do feel free to drop any queries that you have below.
* * *
Originally published on July 7th, 2018 at medium.com